
Insurance claims have a data problem the industry rarely names but pays for every day. Free-text notes, inconsistent formats, information scattered across emails, PDFs, spreadsheets, and legacy systems. It shows up as slow decisions, missed patterns, compliance gaps, and unexplained leakage. And as AI moves deeper into claims, this old problem is taking on a new shape that most insurers have not yet recognised.
The instinct, when people start talking about data quality and AI, is to assume the answer is to clean up the inputs. Force handlers to capture everything in structured fields. Replace free text with dropdowns. Build the perfect form. It is a reasonable instinct, and it is no longer the right one.
What Unstructured Data Actually Looks Like

Unstructured data is anything that does not follow a consistent, machine-readable format. In claims, that is most of what exists. Three assessors record the same outcome as “vehicle total loss,” “write-off,” and “car not repairable.” A handler describes a delay as “awaiting third-party response,” another writes “chasing TP insurer,” a third notes “liability dispute, no movement.” A human reads all of this correctly. A traditional analytics system sees noise.
Multiply that across thousands of claims and years of records and the dataset becomes technically rich but practically unusable. Trends are hard to spot. Leakage hides in the gaps. Compliance reporting becomes a manual exercise in interpretation. The data is there. The structure is not.
See how Curium supports claims teams.
Why the Industry Has Tolerated This

Insurance has lived with this for decades because skilled claims handlers compensate for it. They read context, interpret nuance, and make the right call even when the inputs are inconsistent. The cost is that the intelligence lives in people, not in systems. It does not scale, it creates dependency on individuals, and it makes oversight harder than it should be.
Until recently, the only way to fix this was to force structure at the point of capture. If you wanted clean analytics, you had to make handlers categorise everything in real time. That meant more fields, more dropdowns, more friction in the work. It also meant losing the nuance that free text carries, because the most useful information in a claim file is often the line the handler wrote when no dropdown fit.
Learn more about Curium AI Auto-Detect.
What Has Actually Changed

The reason structured capture used to be the answer is that the tools available to read messy data were limited. Pattern-matching machine learning needed clean inputs to produce reliable outputs. If you wanted AI to do anything useful with claims data, you had to give it data that was already structured.
That constraint has changed. Modern AI is specifically good at exactly the thing claims data has always struggled with. Reading inconsistent, unstructured text and pulling reliable structure out of it is what large language models do best. “Vehicle total loss,” “write-off,” and “car not repairable” are not three different things to a current AI system. They are three ways of saying the same thing, and the model knows it.
This shifts the problem. Unstructured data is no longer the ceiling. The ceiling now is the model you are mapping that data into. Most insurers do not have a coherent one.
Explore Curium’s Claims Platform for Agencies & Insurers.
The Real Bottleneck Is the Schema
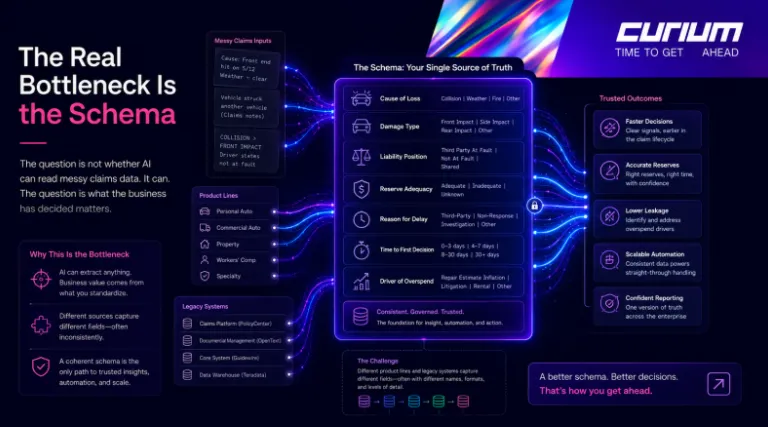
A schema is the defined model of what your business has decided matters about a claim. Cause of loss. Damage type. Liability position. Reserve adequacy. Reason for delay. Time to first decision. Driver of overspend. These are not form fields. They are the questions the business needs answered consistently across every claim, every line of business, every team.
Most insurers do not have a coherent schema. They have a database structure that grew over time, reflecting whatever the original system designers thought to capture, plus a series of patches added by different teams for different reasons. Even when handlers diligently fill in every field, the underlying model of what a claim is differs from one product line to the next. Run analytics on top of that and the results will reflect the inconsistency of the schema, not the reality of the business.
This is the real bottleneck. Cleaning up capture without first sharpening the schema produces tidier-looking data that still cannot answer the questions the business needs answered.
See Curium’s claims platform for agencies and insurers.
Where AI Actually Fits
Once the schema is right, the role of AI becomes clear. It is the bridge between how humans actually work and the structured signal the business needs. Handlers write naturally, in the way that serves the claims process. An AI layer reads what they write and maps it into the schema in the background. The structure shows up in the data without anyone changing how they work.
This is not a hypothetical. It is what we have built our claims technology to do. The technical question is no longer whether AI can read messy claims data. It can. The question is whether the business has done the upstream work to decide what AI should be looking for.
What This Means in Practice
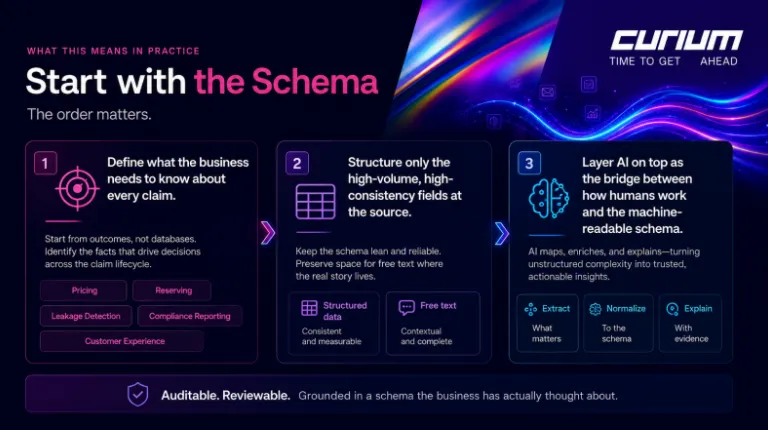
If you are looking at your claims data and wondering where to start, the order matters.
Start with the schema. Decide what you actually need to know about every claim, in language that is consistent across product lines and teams. Pressure-test it against the decisions you want to make. Pricing, reserving, leakage detection, compliance reporting, customer experience. If the schema cannot support the decision, no amount of structured capture will.
Then look at capture, but only where it matters. Some fields genuinely need structure at the source, usually the high-volume, high-consistency ones. Most of the rest can stay as free text, because that is where the real story lives and modern systems can read it.
Then layer AI on top, not as a magic wand but as the connective tissue between human work and machine-readable structure. Auditable. Reviewable. Grounded in a schema the business has actually thought about.
Explore Curium’s Compliance Platform.
The Competitive Picture
The insurers who pull ahead with AI will not be the ones with the cleanest forms or the largest tech budgets. They will be the ones with the clearest model of what a claim is, and the infrastructure to enforce that model without making the work harder. Everything else is a function of that.
The unstructured data problem in claims is real. But the fix is not where most of the industry is looking. The work to do now is upstream of the form, in the model of the business itself.
If you would like to understand how Curium can help you shape the schema your claims function actually needs, and bring modern AI capabilities to bear on the data you already have, we would welcome the conversation.
Author:
Tetiana George, CEO of Curium, Co-Chair of Insurtech Australia and member of ASIC Digital Finance Advisory Committee. LinkedIn Profile.